Track=well 
Data Analysis and Modeling Capstone Project
My capstone is using data from the website Track=well. This site was created to allow users to upload ‘protocols’ and ‘hypothesis tests’ for themselves and others to use with the hopes of croudsourcing data collection and allowing conclusions to be drawn on the ‘protocols’ or experiments being run. For now, Track=well needs to know if it is possible to predict which users will provide the most data and/or when a user might stop using the service. Going forward, it will also be important to know how believable a given users entries are.
Questions
The original questions that the owner of Track=well asked me were:
- Can we develop a score for user participation so I can rank users and find those who are most involved?
- Can we predict whether a user will be more or less involved in the future?
- Can we develop a threshold below which a user isn’t inputting enough data for us to do any analysis?
The questions I am answering in this section are:
- Is there a statistical difference in activity level, days active, and/or amount of data provided by users that signed up due to a large push from a fitness blogger?
- Can we develop a score for user participation so I can rank users and find those who are most involved?
- I am using assigning an activity score per user based on the number of data points they have provided and the number of days they have been active on the service.
- Can we predict whether a user will be more or less involved in the future?
- Ultimatly, the final answer for this question will probably be a time series model. For now, I will see what I can do with logistic modeling.
- I am starting with:
- Can we predict if a user will be involved at all based on their profile data?
- If I have time, I will also look at:
- Can we predict which users will go inactive based on their profile data?
- If they will be active, can we predict if they will complete a protocol?
- If they will be involved, can we prodict how involved based on their profile data?
- Based on past involvement or profile data, can we predict how long a user will remain active?
- Based on past involvement or profile data, can we predict how long a user will go inactive?
Exploratory Data Analysis and Data Cleaning/Creation
There are no pre-defined site involvment levels, tracking of how long a user has been active/inactive or other metric tracking so those features will have to be created from existing data.
- days_active: (last date a user entered data on the site) - (the day the user signed up on the site)
- days_inactive: (day data was pulled) - (last date a user entered data on the site)
- user_data_cnt: (number of unique, non-null data points associated with their profile data) + (number of followup entries)
- user_activity_score: (user_data_cnt) / (days_active)
- user_active_yn: yes if user activity score is above 0
There appears to have been a manual data load into the database at somepoint as there are some users with 0-1 Total days active but 2000 data points. In those cases, the first date with an entry assigned to it will take the place of theire sign up date. Profile data was also manipulated to determine if the data entered or the the fact that anything was entered was more important to predicting future activity. For features with a lot of nulls, I chose between assuming the median value for the field or dropping the feature on a per feature basis. I made the decision based on the likelihood of the median value being correct. For example, I dropped the raw blood type feature after determinning if it was answered or not because I have no way of knowing which blood type is correct but I assumed a null in married simply meant no because there weren’t very many nulls for the feature and I assume a person is more likely to answer a question they feel pertains to them. I wanted to keep as many features early on as possible as I didn’t know if bothering to answer the questions was actually more important than the final answer provided. For profile fields that were open text, I took a character count as the simplest way of summarizing the complexity of their input. Once I created a numeric represintative for the text fields, I dropped them from modeling.
- usual_activity_len: the character count of the entry in the usual_activity field
- dup_protocol_started: changed to a yes/no instead of actual protocol hashes
- dup_protocol_finished: changed to a yes/no instead of actual protocol hashes
- usual_medications_len: the character count of the entry in the usual_medications field
- married_answered: changed to yes/no for if the queston was answered
- menstruation_answered: changed to yes/no for if the queston was answered
- bio_sex_answered: changed to yes/no for if the queston was answered
- blood_type_answered: changed to yes/no for if the queston was answered
- pregnant_answered: changed to yes/no for if the queston was answered
- caffeine_answered: changed to yes/no for if the queston was answered
- alcohol_answered: changed to yes/no for if the queston was answered
- smoke_answered: changed to yes/no for if the queston was answered
- usual_diet_len: the character count of the entry in the usual_diet field
- usual_conditions_len: the character count of the entry in the usual_conditions field
- dup_protocol_active: changed to a yes/no instead of actual protocol hashes
- height_likelihood: the probability that the height reported exists in the adult population
- This was determined with a very forgiving normal distribution based on the average of the mean heights for men and women and adding together the standard distribution for the two groups. It is not meant to predict if they were accurate but to simply show where heights provided were not feasible (40 cm for example).
I later came back and dropped both dup_protocol_finished and dup_protocol_active because they were systematically set regardless of user interaction after a protocol was started.
Features that will probably be useful in the future but haven’t been created yet:
- Change User Active YN to User Active Ever YN and User Currently Active YN
- Longest time between logins
- Current time since last login
- Months since signup
- Entries Other Than Profile YN
- Number of protocols signed up for
- Which protocol(s) signed up for
- How they found the site
- Which medications each person is on
- What pre-existing conditions they have
- Number of protocols completed
- Likelihood of inputs for the entries (similar to likelihood of height) would need to be written on a per entry-type basis to determine if someone’s data in a given protocol can be used towards completing that protocol’s hypothesis test.
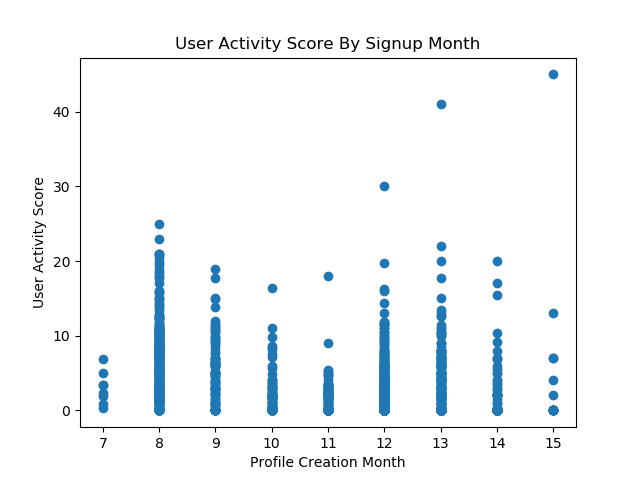
Because these features are based on existing features, there are likely to be highly correlated sets in the full feature map. I intend to pick only some of the features, avoiding correlated groups, for the final models. For most of my analysis, I was looking at 2933 unique users with about 30 features.
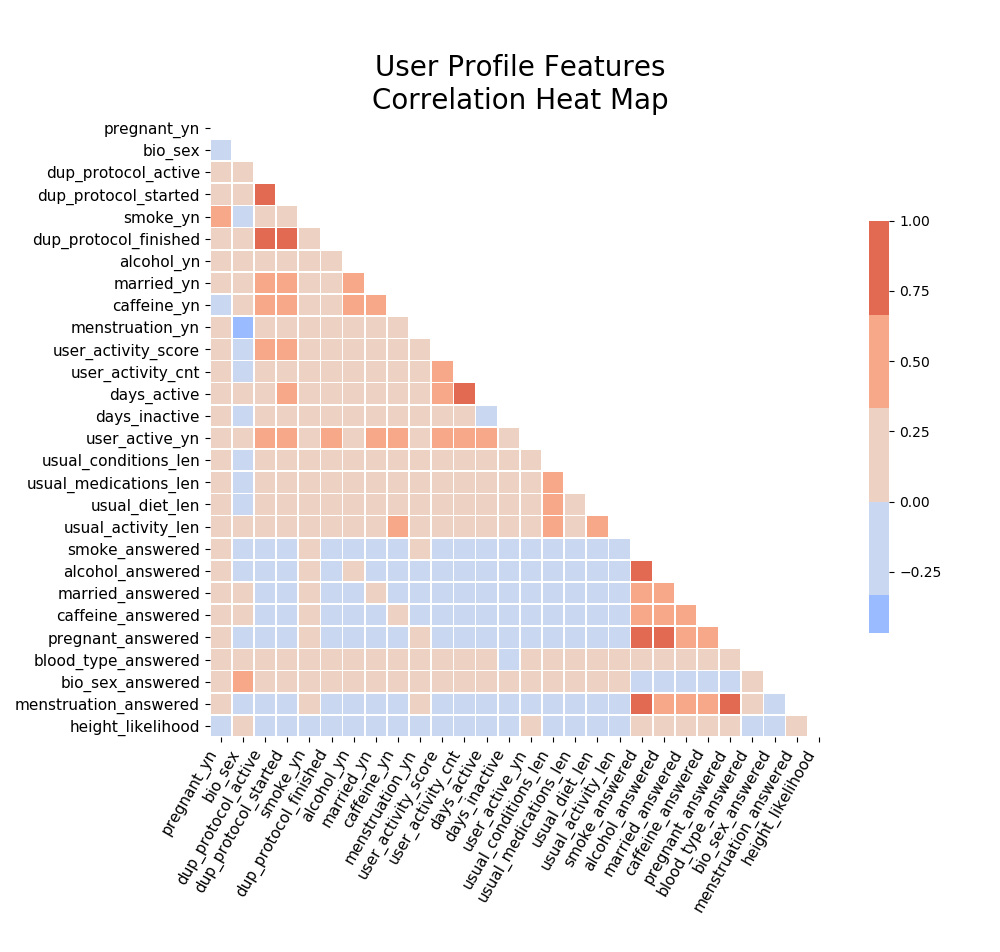
I later came back to check correlations specifically in the features suggested by my lasso regression models:
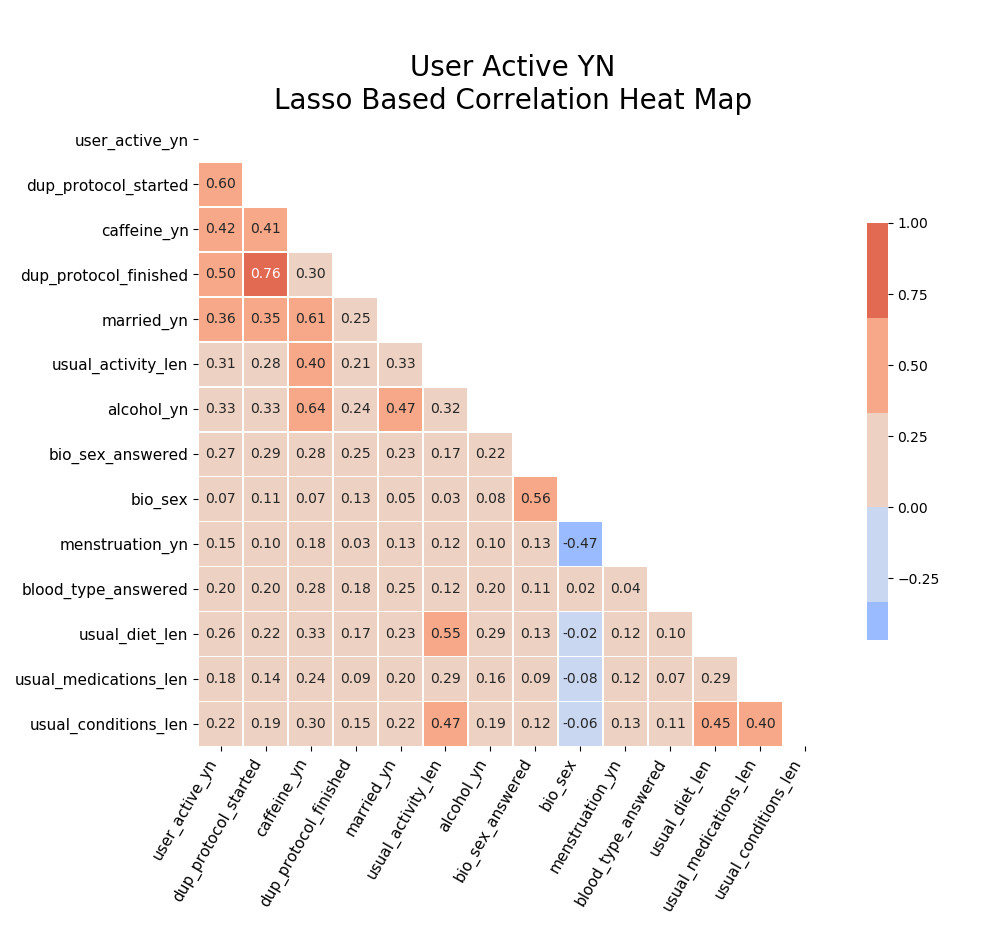
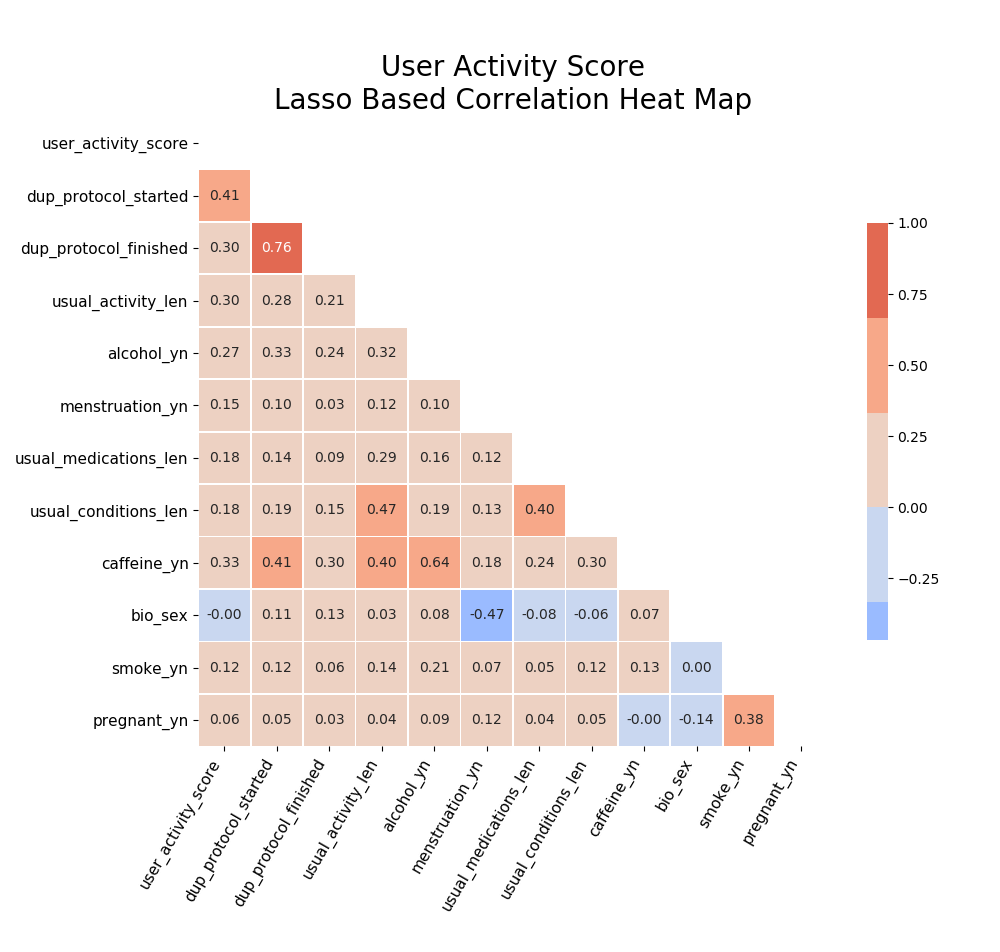
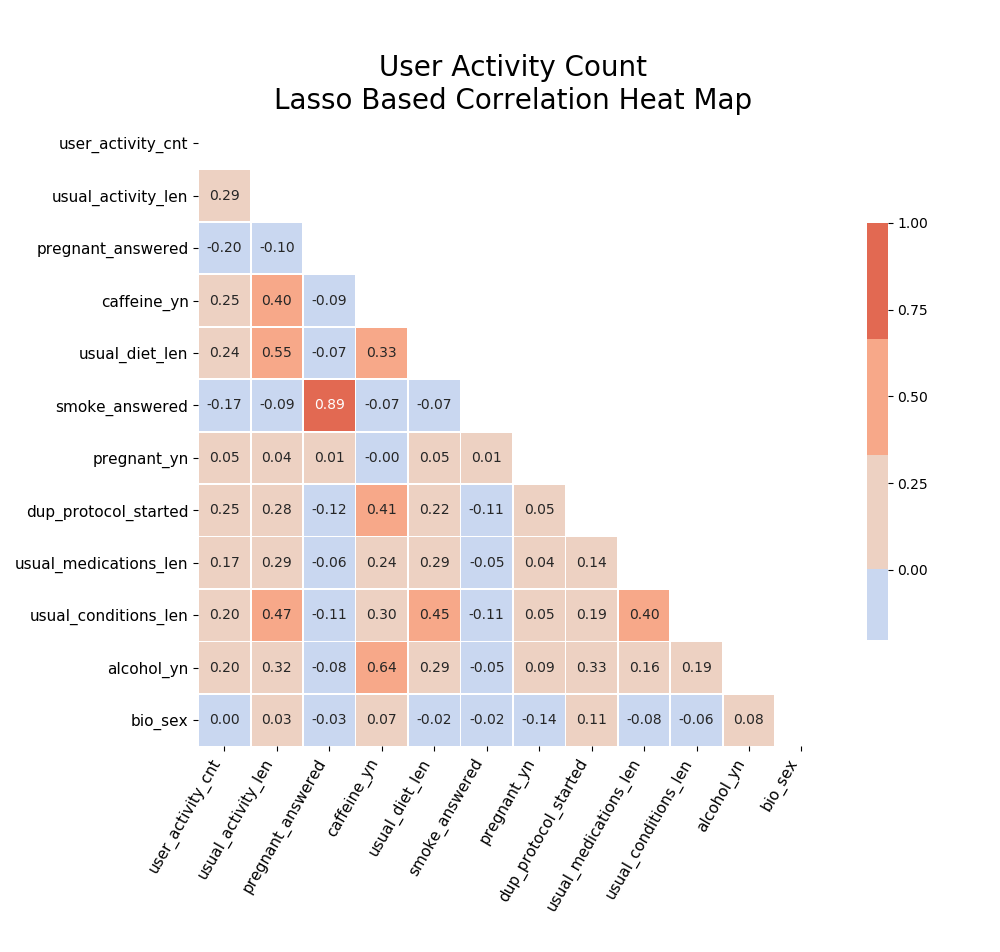
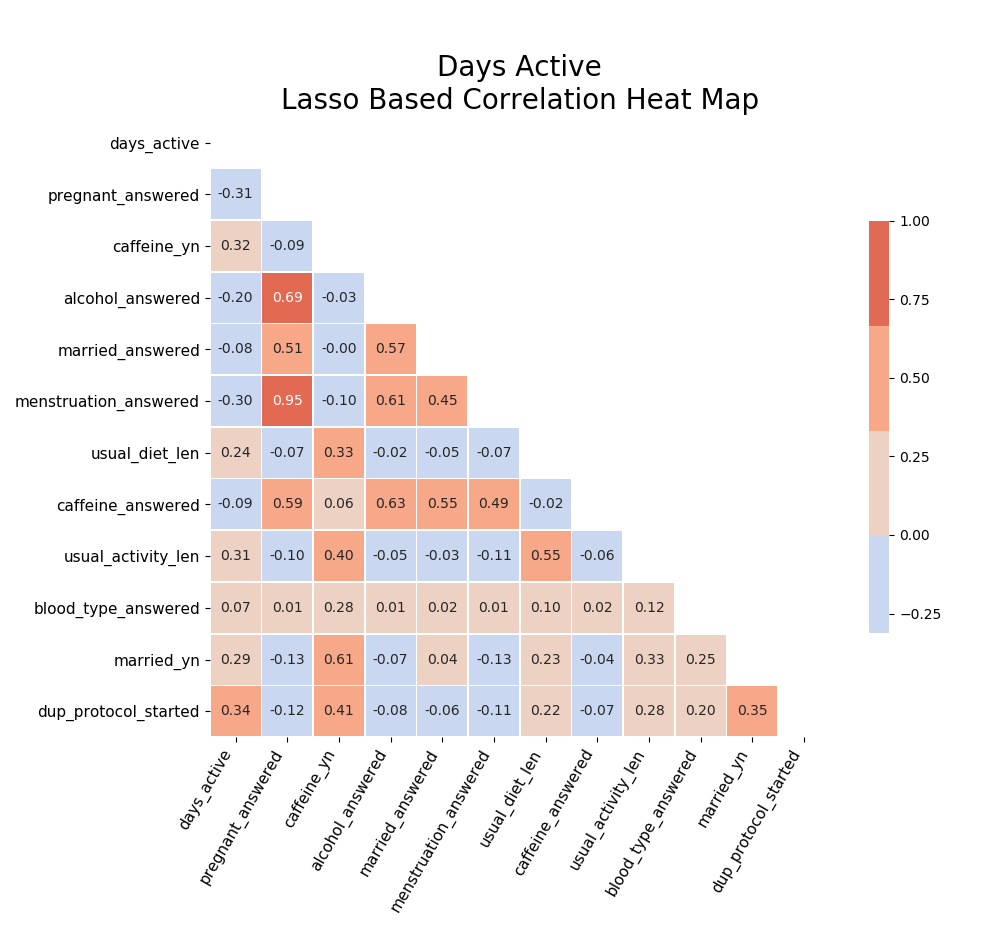
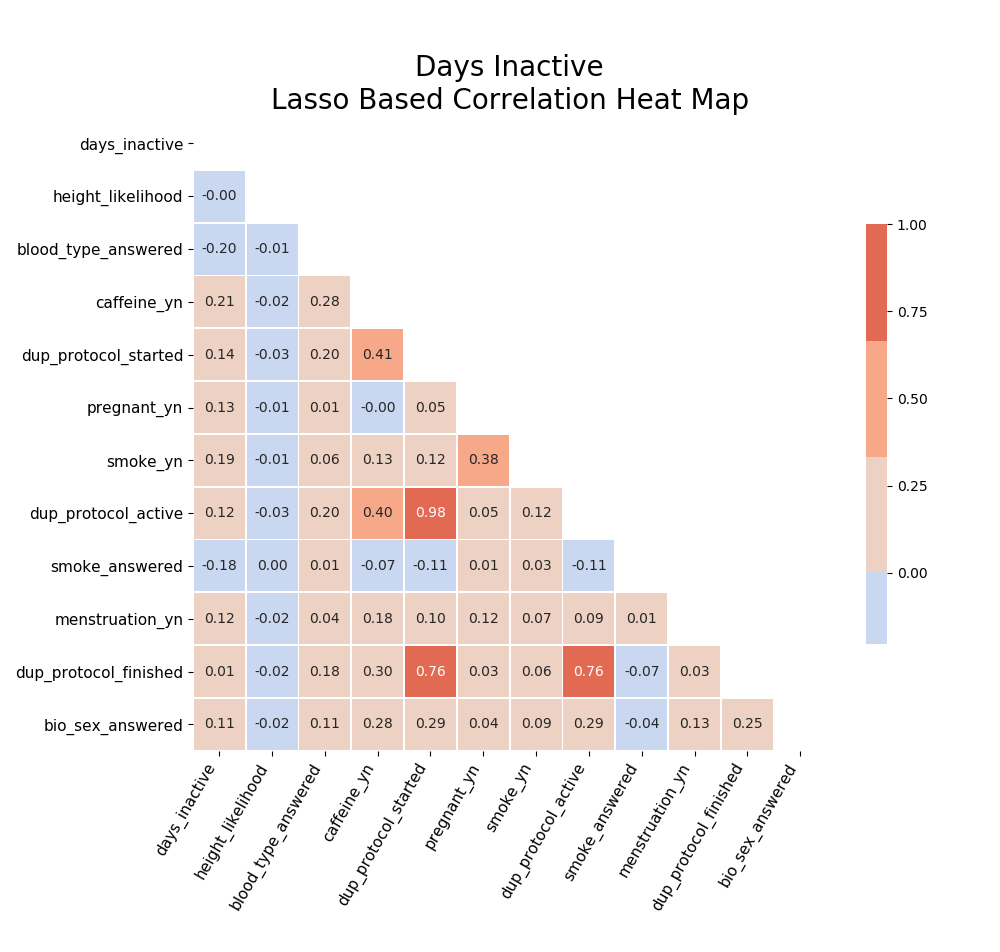
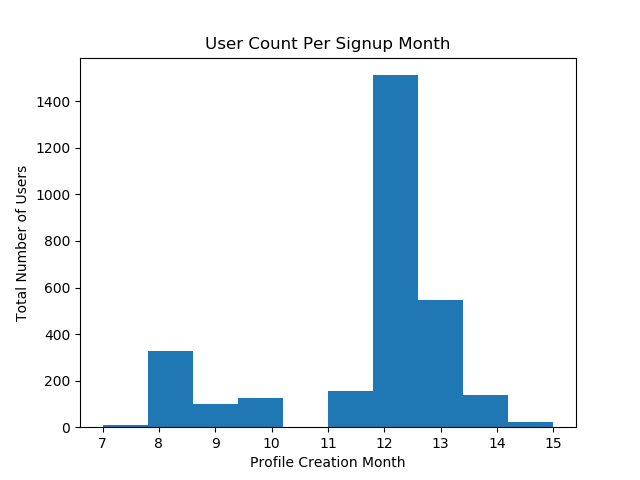
After going back and fixing for the dataload, the timebased correlations became more obviouse:
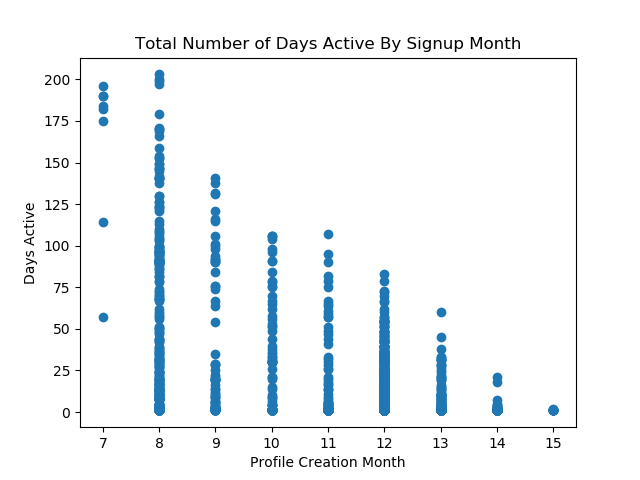
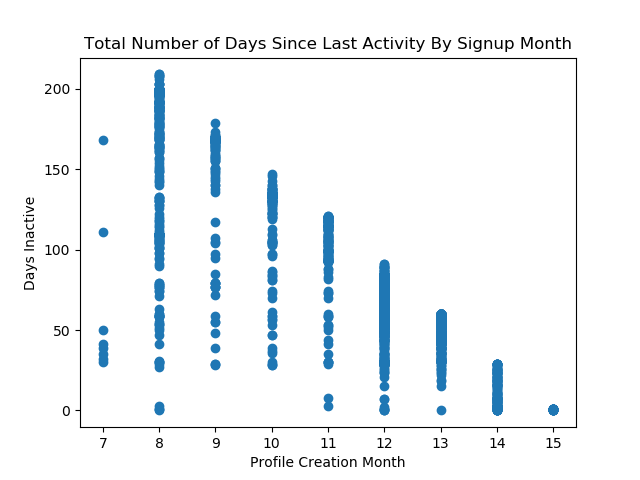
And the thought that the blogger’s push for January activity (people signing up in December to start in January) was helpful in increasinng the percentage of involvement becomes less likely, though it does seem to have pushed a higher volume of people to the site:
Hypothesis Test
Question: Is there a statistical difference in activity level for users that signed up due to a large push from a fitness blogger when compared with everyone else?
H0: There is no difference in involvment metrics for Dec when compared to the rest of the year.
H1: There is a difference in involment metrics for Dec when compared to the rest of the year.
alpha: .025 = (.05/2)
I used a two population t-test for each metric to determine if there was a statistical differance. Due to the time sequence effect on Days Active and Days Inactive, I decided not to include them in the testinng as a difference between Dec and the rest of the year could simply be due to people signing up in Dec having less time to be active or inactive on the service.
TTest Assumptions:
- Independent observations: Each record is a seperate and unique account. No account can have two creation months.
- Homogeneity: The standard deviations are very close for the YN populations but are different for the Score populations.
- Normality: bootstrapped sample means for each population in each test. Because of this, I limited the Score populations to only users who were active (removing all the zeros that are covered in the YN question).
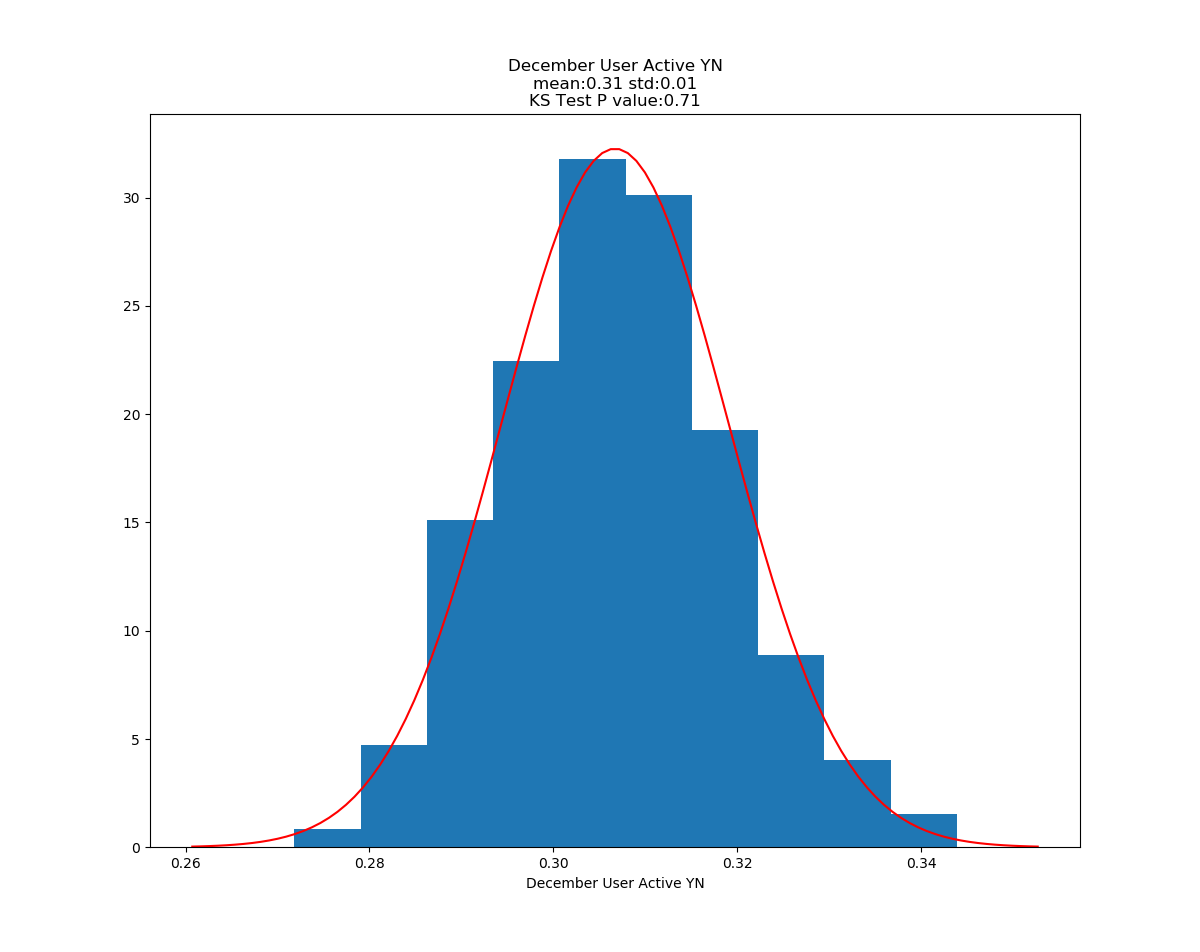
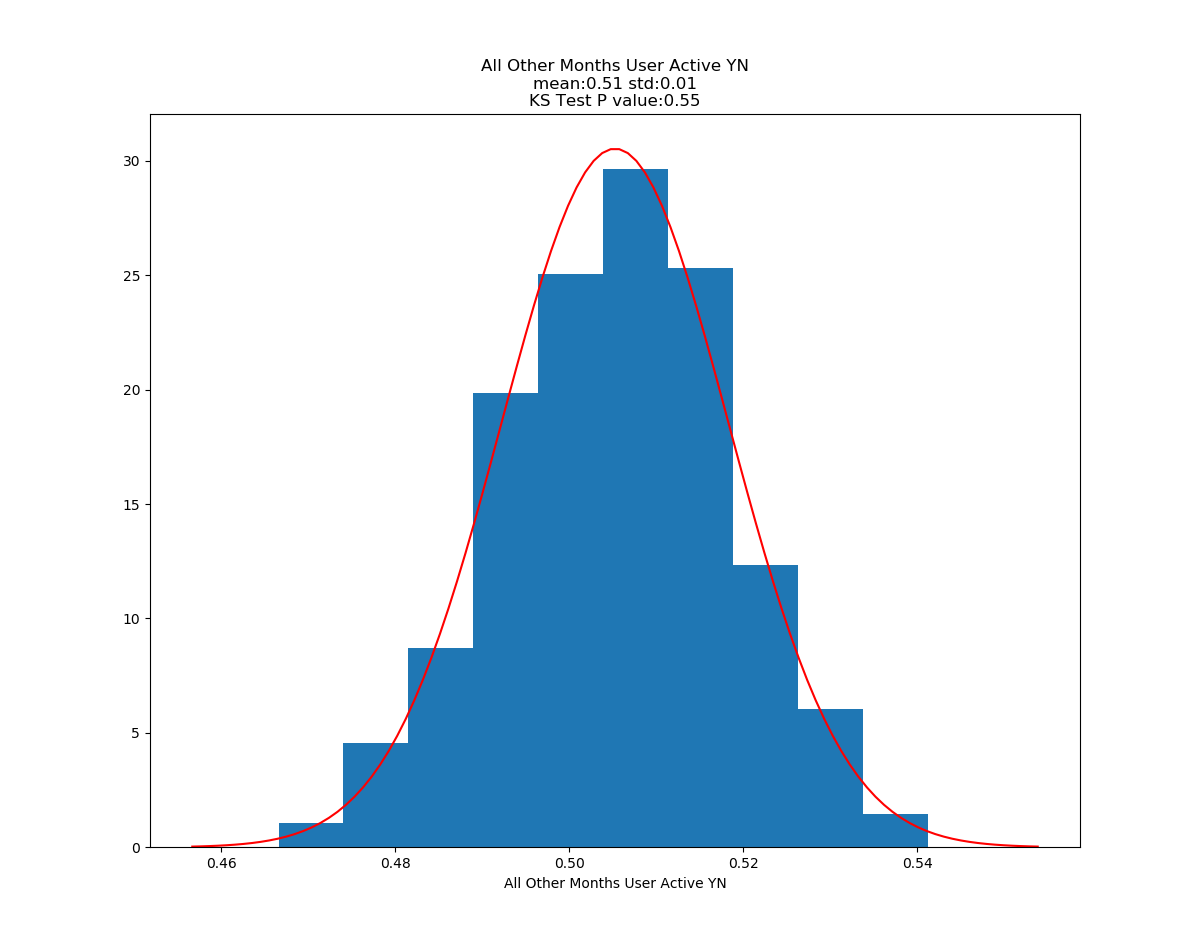
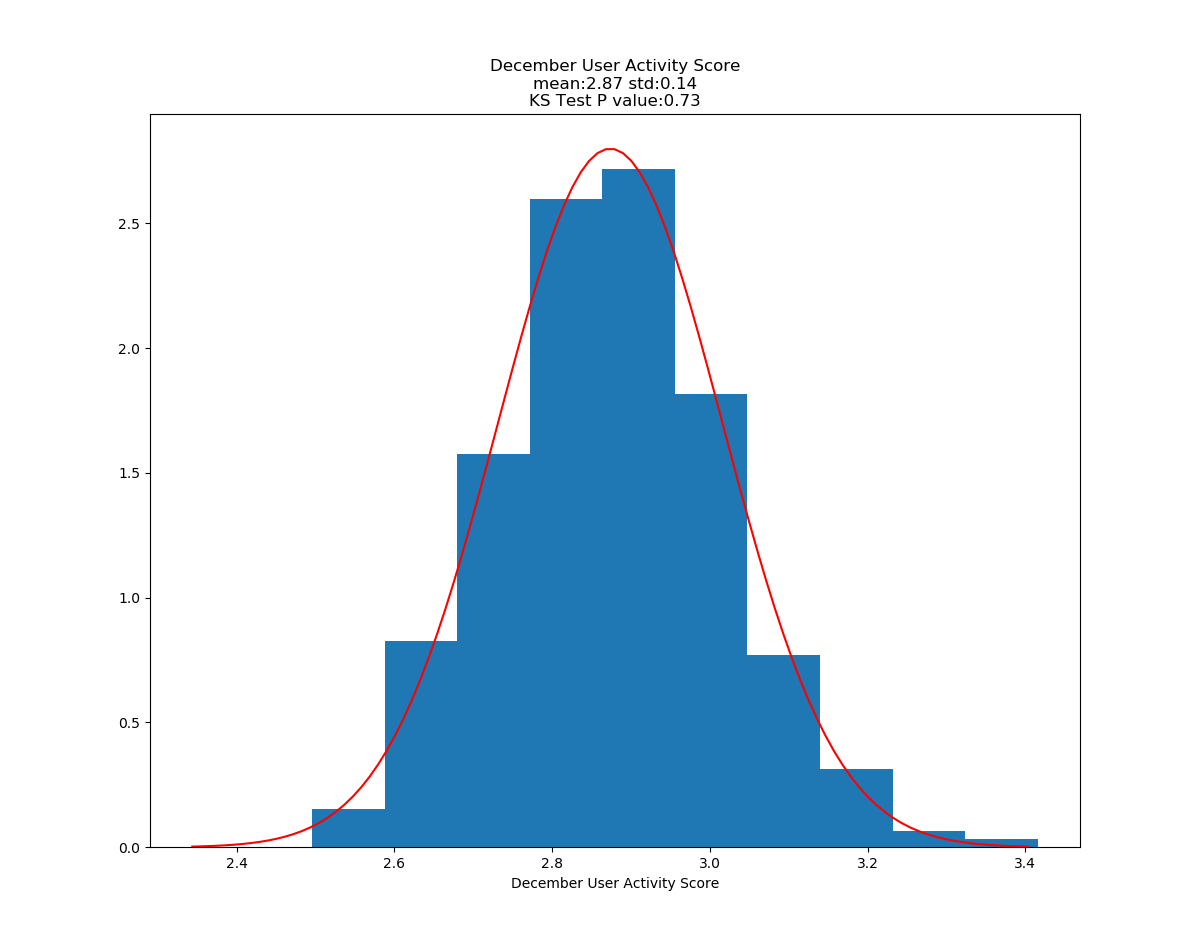
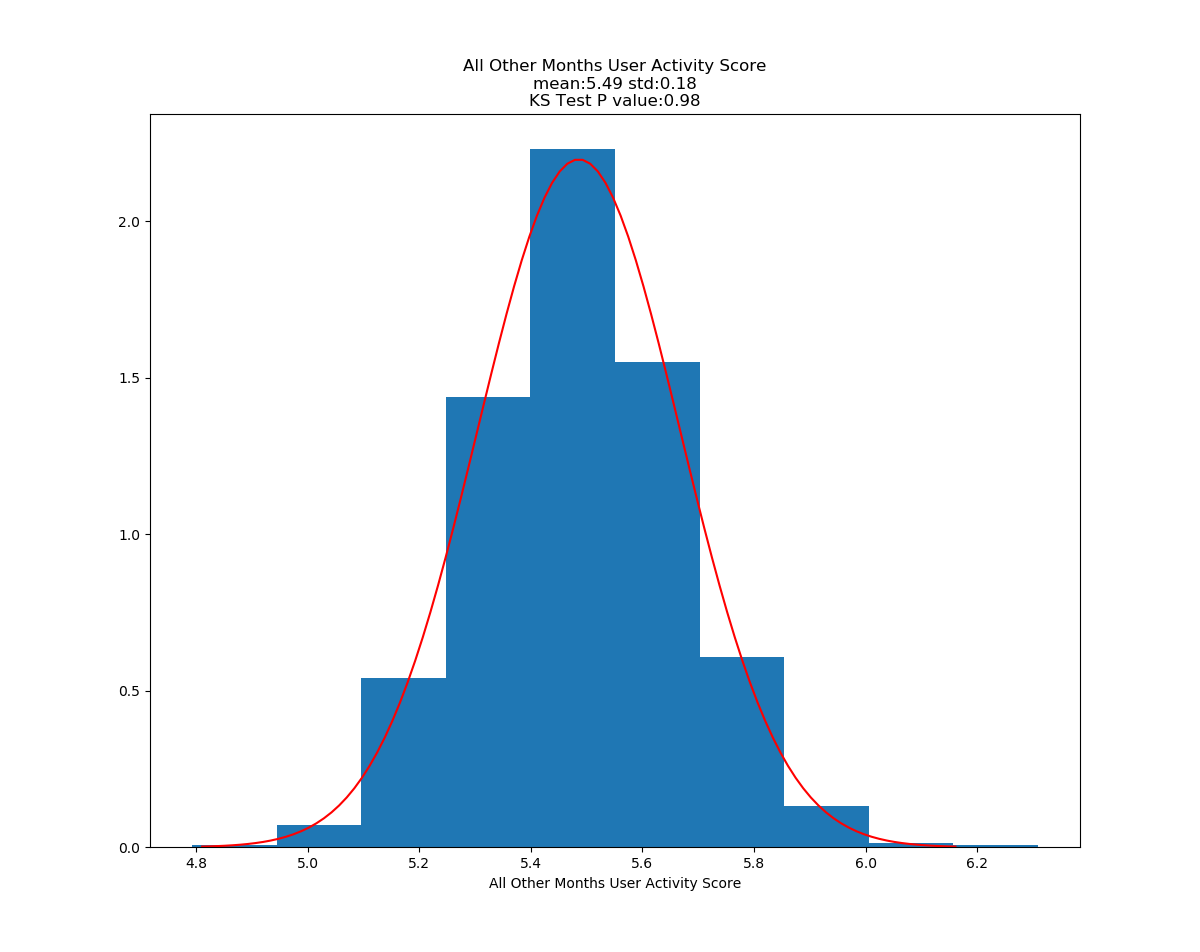
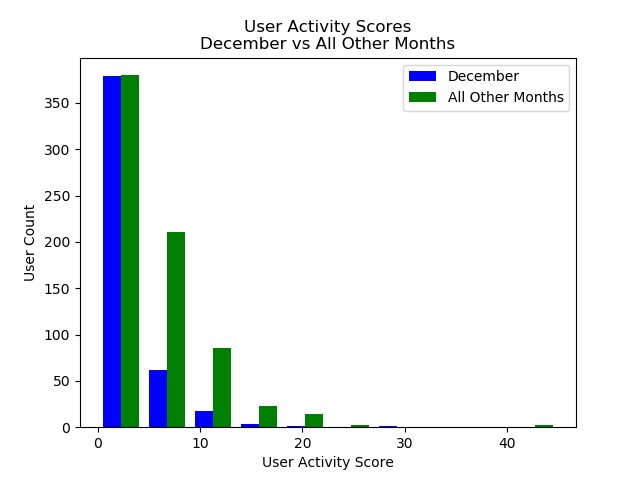
Running ttest on User Activity Scores for Dec vs all other months
Dec Average: 2.87
Year Average: 5.49
Ttest_indResult(statistic=-9.37, pvalue=5.41e-20)
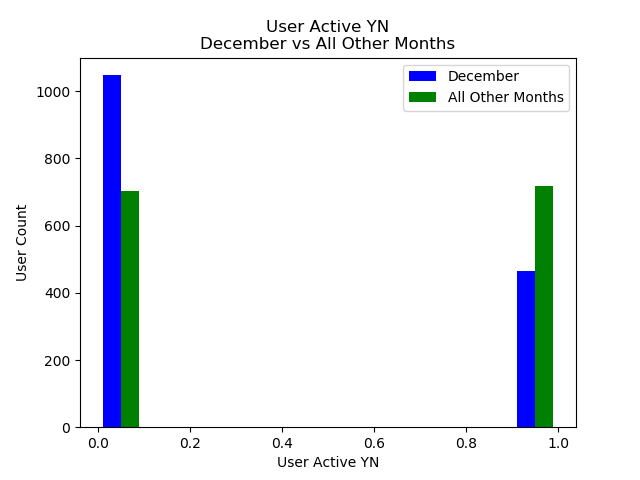
Running ttest on Users Active YN for Dec vs all other months
Dec Average: 0.31
Year Average without Dec: 0.50
Ttest_indResult(statistic=-10.66, pvalue=4.79e-26)
Conclusion: In metrics that have been normalized for total time on the system, there does appear to be a statisticaly significant difference in users who signed up in December and all other users as far as initial decisions to use or not use the site go. There is also a statistically significant difference in how active the users are if they decided to user the system after signing up. Unfortunantly, this segment of users appear to be less likely to be active at all and less likely to upload a large amount of data.
Logistic Regression
Lasso to Pick Features
I am using a Lasso Regression model on my standardized data to assist in picking which features I should include in my final model. Features with a 0 coefficient in this test will have practically no value in my models.
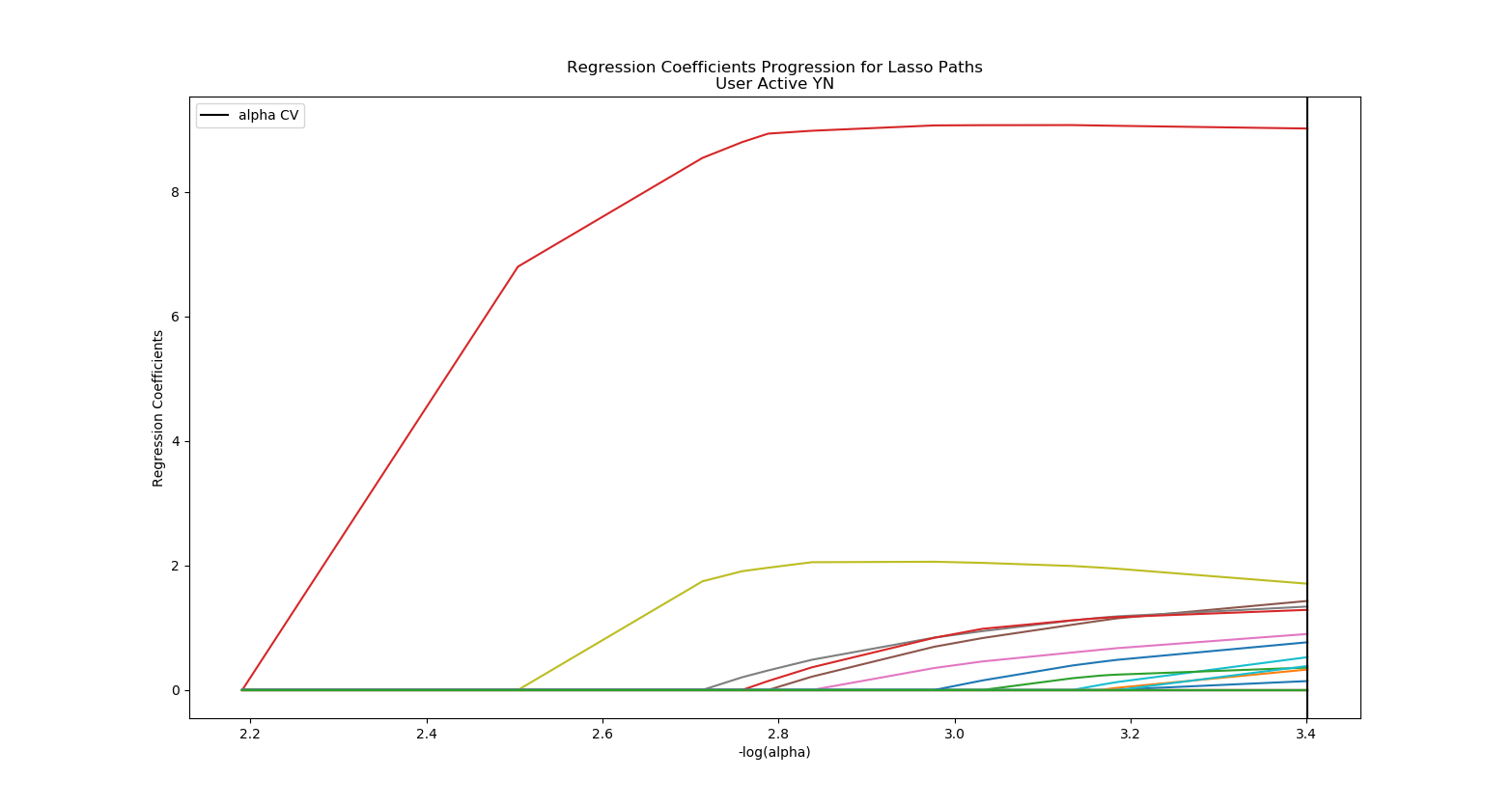
coefficients predictors sort
3 0.199714 dup_protocol_started 0.199714
8 0.037674 caffeine_yn 0.037674
5 0.031455 dup_protocol_finished 0.031455
7 0.029471 married_yn 0.029471
13 0.027493 usual_activity_len 0.027493
6 0.019620 alcohol_yn 0.019620
20 0.016918 bio_sex_answered 0.016918
9 0.011760 menstruation_yn 0.011760
19 0.008540 blood_type_answered 0.008540
12 0.008184 usual_diet_len 0.008184
11 0.006984 usual_medications_len 0.006984
10 0.003065 usual_conditions_len 0.003065
16 0.000000 married_answered 0.000000
21 0.000000 menstruation_answered 0.000000
18 0.000000 pregnant_answered 0.000000
17 0.000000 caffeine_answered 0.000000
0 0.000000 pregnant_yn 0.000000
15 0.000000 alcohol_answered 0.000000
14 0.000000 smoke_answered 0.000000
1 0.000000 bio_sex 0.000000
4 0.000000 smoke_yn 0.000000
2 0.000000 dup_protocol_active 0.000000
22 0.000000 height_likelihood 0.000000
Out of curiosity, I went ahead and did the Lasso Regression on the other activity metrics I created. I will be creating predictive models for them over time.
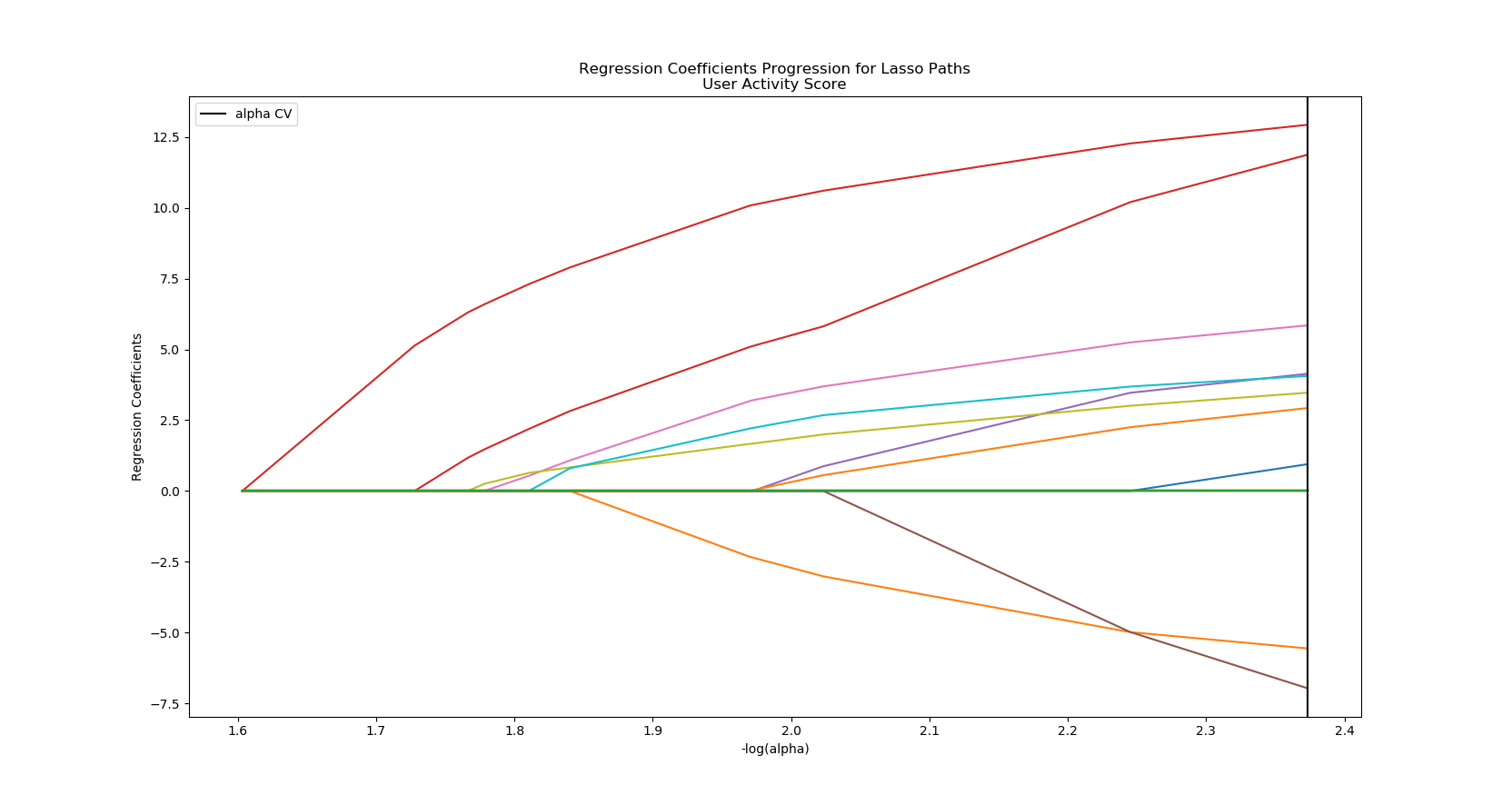
coefficients predictors sort
3 0.434011 dup_protocol_started 0.434011
13 0.421182 usual_activity_len 0.421182
5 -0.245248 dup_protocol_finished 0.245248
6 0.203033 alcohol_yn 0.203033
1 -0.191818 bio_sex 0.191818
4 0.146544 smoke_yn 0.146544
9 0.140283 menstruation_yn 0.140283
8 0.121382 caffeine_yn 0.121382
11 0.103242 usual_medications_len 0.103242
0 0.032777 pregnant_yn 0.032777
10 0.000000 usual_conditions_len 0.000000
7 0.000000 married_yn 0.000000
12 0.000000 usual_diet_len 0.000000
2 0.000000 dup_protocol_active 0.000000
14 0.000000 smoke_answered 0.000000
15 0.000000 alcohol_answered 0.000000
16 0.000000 married_answered 0.000000
17 0.000000 caffeine_answered 0.000000
18 0.000000 pregnant_answered 0.000000
19 0.000000 blood_type_answered 0.000000
20 0.000000 bio_sex_answered 0.000000
21 0.000000 menstruation_answered 0.000000
22 0.000000 height_likelihood 0.000000
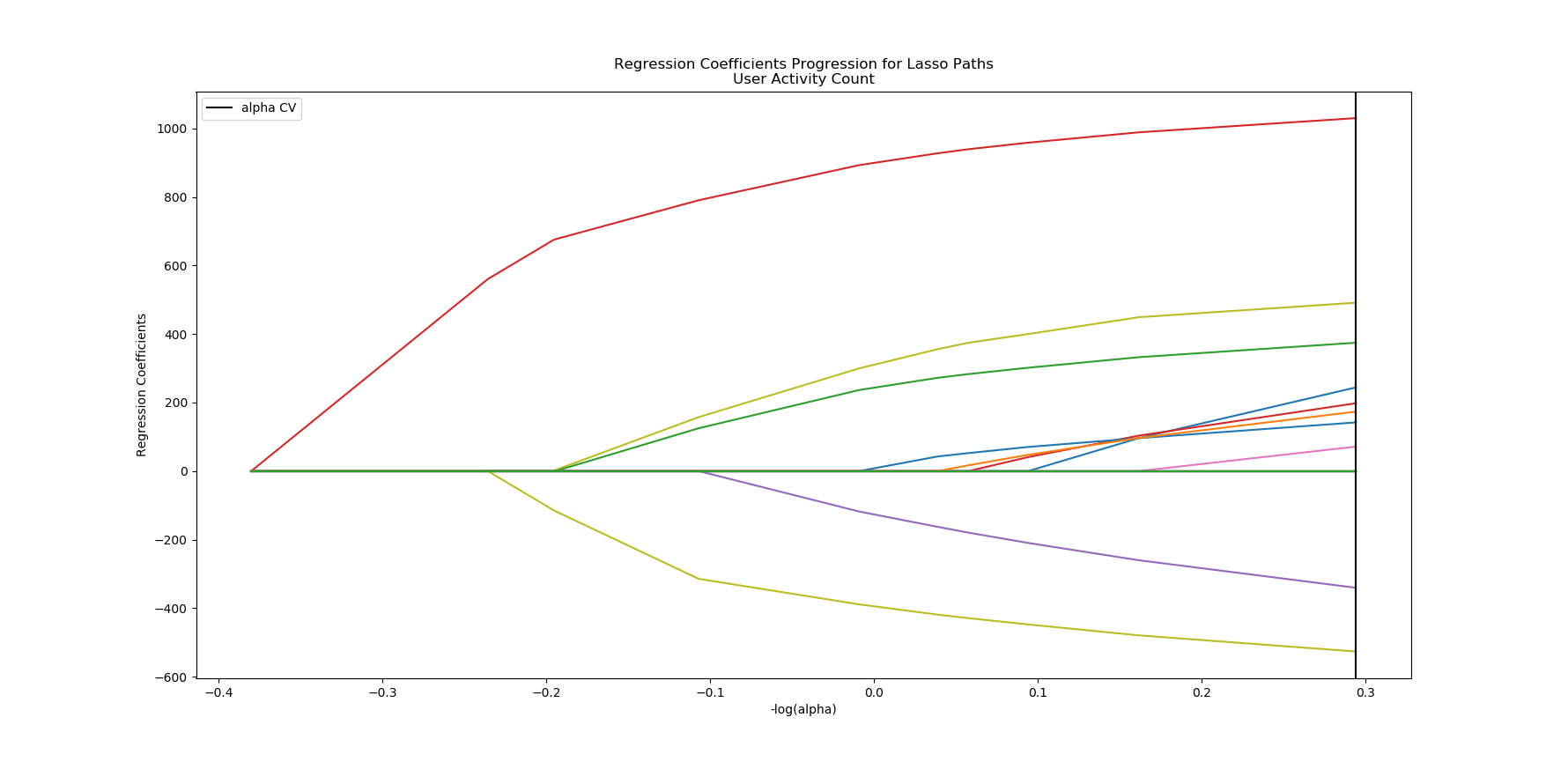
coefficients predictors sort
13 35.409223 usual_activity_len 35.409223
18 -17.519923 pregnant_answered 17.519923
8 17.065931 caffeine_yn 17.065931
12 13.678984 usual_diet_len 13.678984
14 -11.344958 smoke_answered 11.344958
0 8.460380 pregnant_yn 8.460380
3 6.816043 dup_protocol_started 6.816043
11 5.861865 usual_medications_len 5.861865
10 5.292121 usual_conditions_len 5.292121
6 2.476444 alcohol_yn 2.476444
7 0.000000 married_yn 0.000000
9 0.000000 menstruation_yn 0.000000
1 0.000000 bio_sex 0.000000
5 0.000000 dup_protocol_finished 0.000000
4 0.000000 smoke_yn 0.000000
15 0.000000 alcohol_answered 0.000000
16 0.000000 married_answered 0.000000
17 0.000000 caffeine_answered 0.000000
2 0.000000 dup_protocol_active 0.000000
19 0.000000 blood_type_answered 0.000000
20 0.000000 bio_sex_answered 0.000000
21 0.000000 menstruation_answered 0.000000
22 0.000000 height_likelihood 0.000000
User Days Actiive Coefficients: 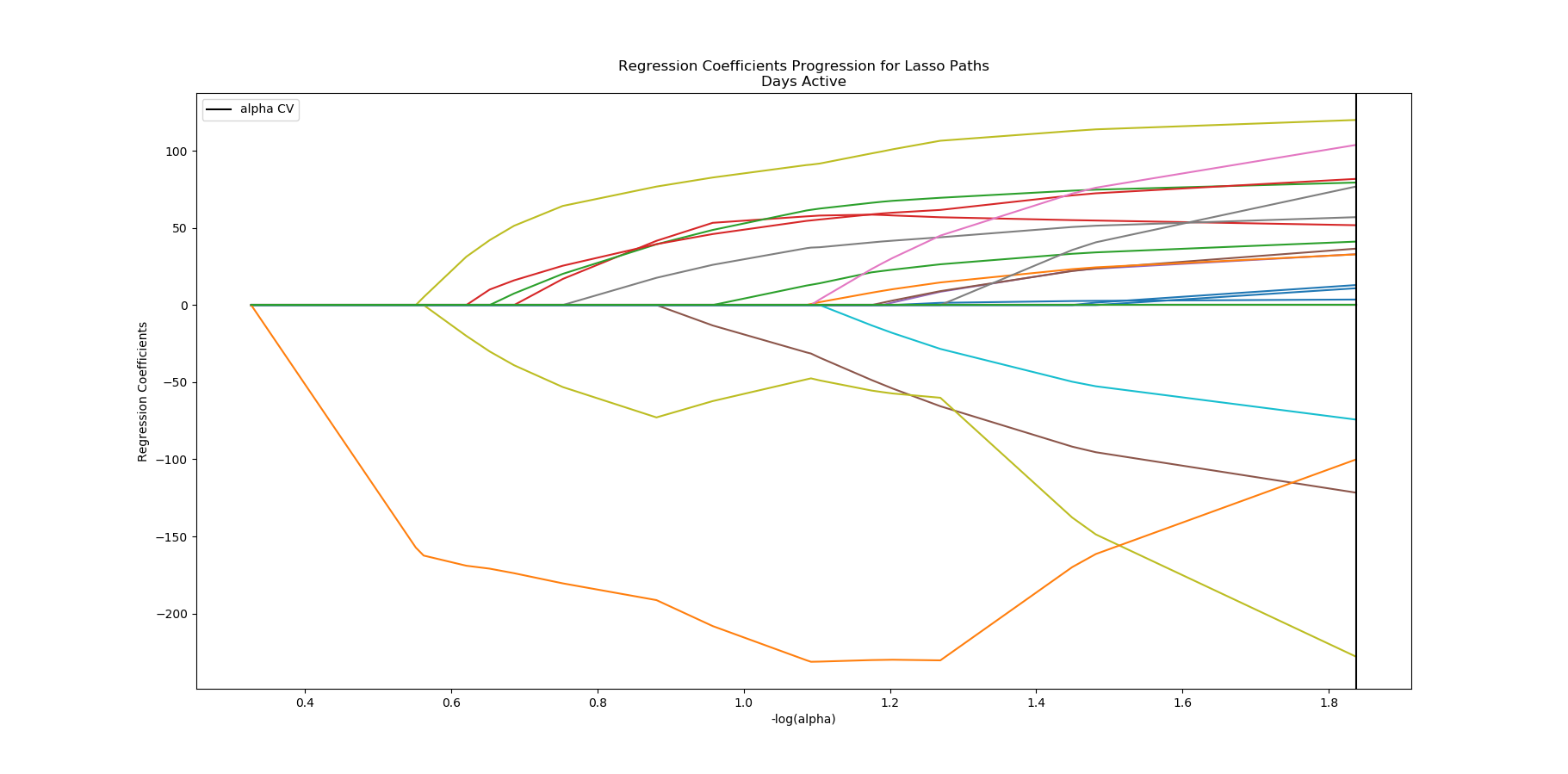
coefficients predictors sort
18 -7.939721 pregnant_answered 7.939721
8 4.175520 caffeine_yn 4.175520
15 -4.164881 alcohol_answered 4.164881
16 3.820201 married_answered 3.820201
21 -3.396733 menstruation_answered 3.396733
12 3.377943 usual_diet_len 3.377943
17 2.885086 caffeine_answered 2.885086
13 2.756762 usual_activity_len 2.756762
19 -2.514606 blood_type_answered 2.514606
7 1.986782 married_yn 1.986782
3 1.754221 dup_protocol_started 1.754221
2 1.399556 dup_protocol_active 1.399556
5 1.265259 dup_protocol_finished 1.265259
11 1.262112 usual_medications_len 1.262112
4 1.176299 smoke_yn 1.176299
0 0.432050 pregnant_yn 0.432050
20 0.397348 bio_sex_answered 0.397348
10 0.128824 usual_conditions_len 0.128824
14 0.000000 smoke_answered 0.000000
1 0.000000 bio_sex 0.000000
9 0.000000 menstruation_yn 0.000000
6 0.000000 alcohol_yn 0.000000
22 0.000000 height_likelihood 0.000000
User Days Inactive Coefficients: 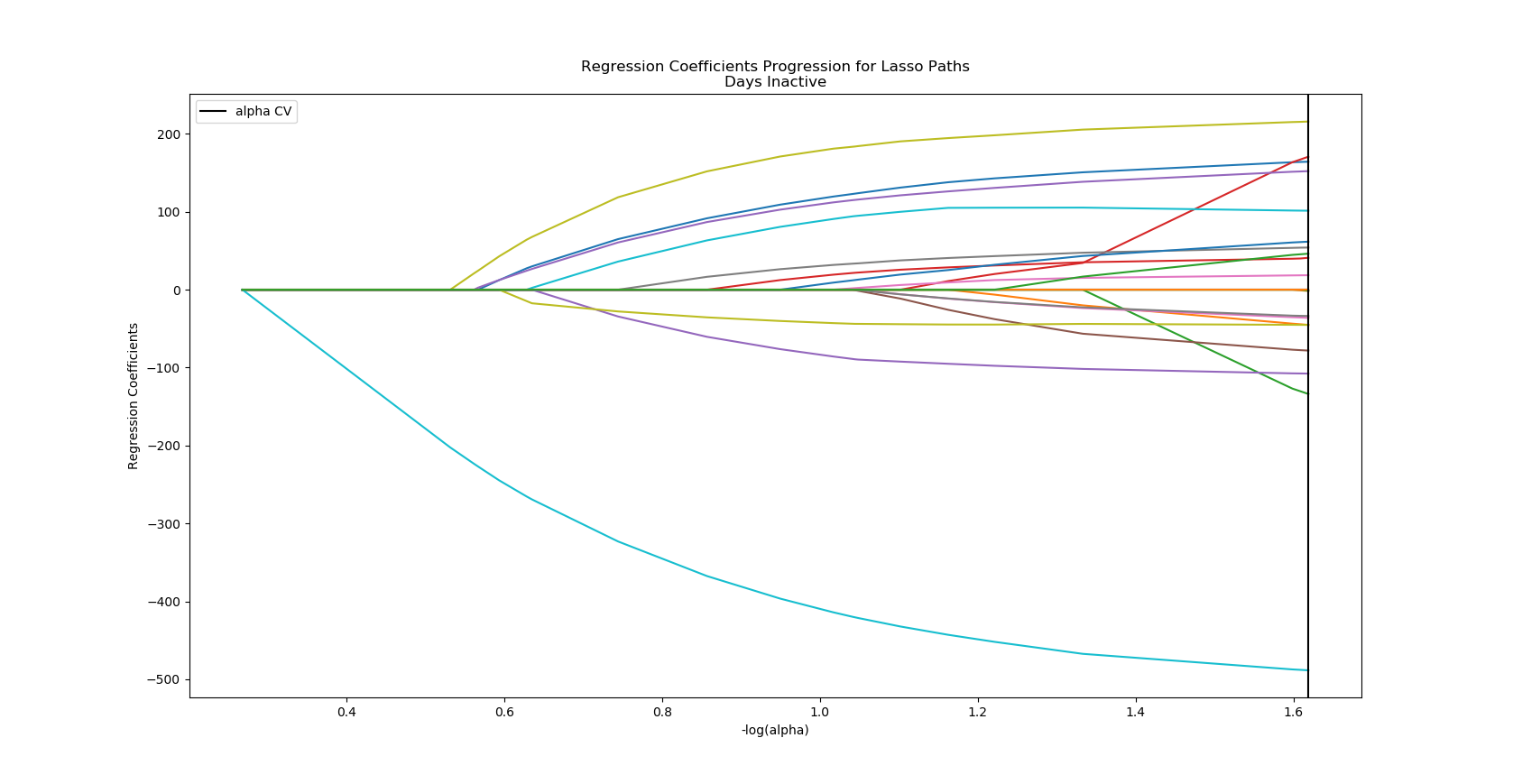
coefficients predictors sort
22 16.926637 height_likelihood 16.926637
19 -16.544399 blood_type_answered 16.544399
8 7.583835 caffeine_yn 7.583835
3 6.295368 dup_protocol_started 6.295368
0 5.470116 pregnant_yn 5.470116
4 5.255658 smoke_yn 5.255658
2 -4.857834 dup_protocol_active 4.857834
14 -3.655486 smoke_answered 3.655486
9 3.530928 menstruation_yn 3.530928
5 -2.756194 dup_protocol_finished 2.756194
20 2.196281 bio_sex_answered 2.196281
7 1.882430 married_yn 1.882430
1 -1.565740 bio_sex 1.565740
13 1.498393 usual_activity_len 1.498393
18 -1.481262 pregnant_answered 1.481262
16 -1.330033 married_answered 1.330033
17 -1.097371 caffeine_answered 1.097371
6 0.645090 alcohol_yn 0.645090
11 -0.050747 usual_medications_len 0.050747
12 -0.039863 usual_diet_len 0.039863
10 0.000000 usual_conditions_len 0.000000
15 0.000000 alcohol_answered 0.000000
21 0.000000 menstruation_answered 0.000000
Logistic Regression on User Active YN
I with my standardized data and using all the predictors selected from my Lasso Regression in a basic Logistic Regression model. With just a train/test split on the Logistic Regression I got:
Mean accuracy of logistic regression classifier on test set: 0.78
[[357 163]
[ 32 328]]
tn, fp
fn, tp
estimatedCoefficients features sort
0 1.409541 dup_protocol_started 1.409541
5 0.350281 bio_sex_answered 0.350281
3 0.277375 usual_activity_len 0.277375
1 0.221156 caffeine_yn 0.221156
7 0.150474 menstruation_yn 0.150474
2 0.117282 married_yn 0.117282
8 0.113480 blood_type_answered 0.113480
11 0.107046 usual_conditions_len 0.107046
9 0.095546 usual_diet_len 0.095546
10 0.055545 usual_medications_len 0.055545
4 0.049206 alcohol_yn 0.049206
6 0.032716 bio_sex 0.032716
Estimated intercept: [-0.79332413]
That model with KFold cross validation:
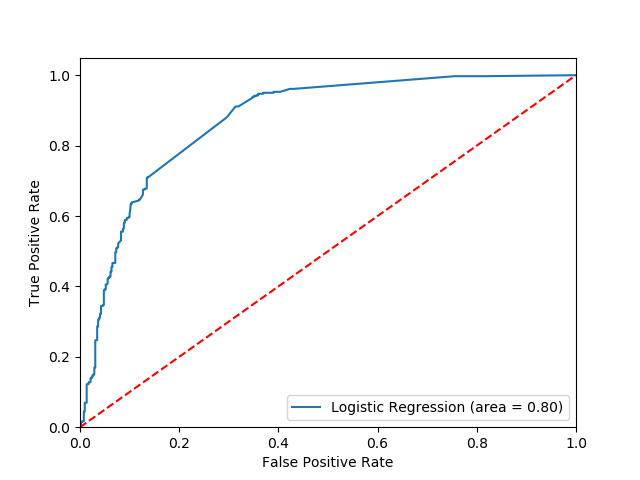
10-fold cross validation average accuracy: 0.80
10-fold cross validation average recall: 0.90
10-fold cross validation average precision: 0.69
precision recall f1-score support
0 0.92 0.69 0.79 520
1 0.67 0.91 0.77 360
avg / total 0.82 0.78 0.78 880
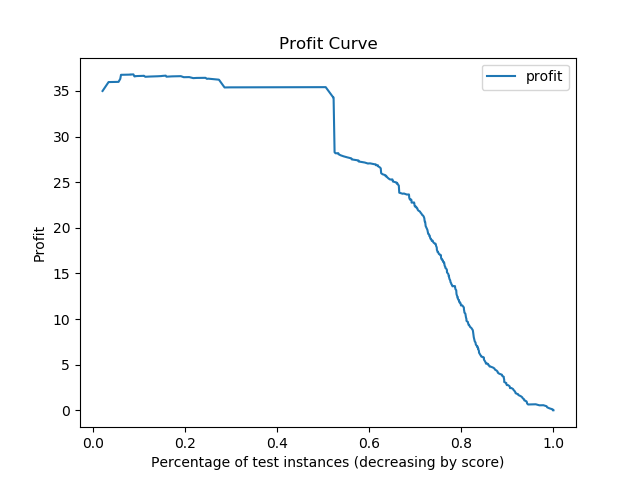
The profit curve based on TP = 100, FP = -10 and no cost for FN or TN is shown below. This cost matrix was created after speaking with the owner of Track=well and determining that he would use this model to identify users worth advertising to and focusing support on. The current values are estimates and not officiall from Track-well at this time.
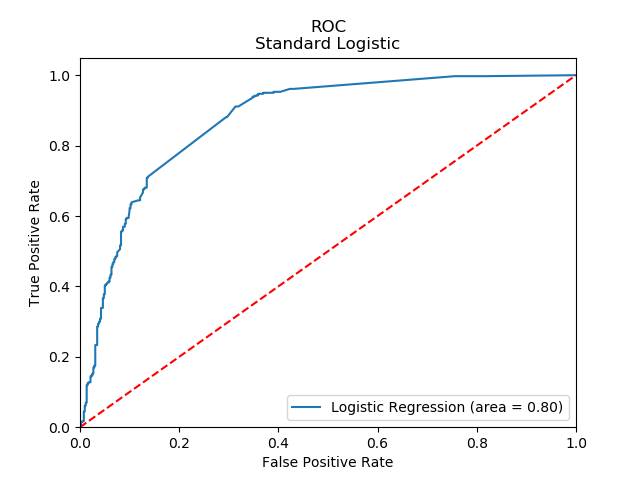
The results from a basic logistic regression surprised me. The model is consistently 1 bias when the data is actually 0 bias.
I then tried with a balanced class weight in the logistic model, but it didn’t make very much differance.
Mean accuracy of logistic regression classifier on test set: 0.78
[[357 163]
[ 32 328]]
tn, fp
fn, tp
estimatedCoefficients features sort
0 1.400781 dup_protocol_started 1.400781
5 0.350908 bio_sex_answered 0.350908
3 0.275247 usual_activity_len 0.275247
1 0.218432 caffeine_yn 0.218432
7 0.153701 menstruation_yn 0.153701
8 0.117778 blood_type_answered 0.117778
2 0.112738 married_yn 0.112738
11 0.112275 usual_conditions_len 0.112275
9 0.094277 usual_diet_len 0.094277
10 0.049746 usual_medications_len 0.049746
4 0.038385 alcohol_yn 0.038385
6 0.030113 bio_sex 0.030113
Estimated intercept: [-0.38602606]
With KFold cross validation
10-fold cross validation average accuracy: 0.80
10-fold cross validation average recall: 0.90
10-fold cross validation average precision: 0.69
precision recall f1-score support
0 0.92 0.69 0.79 520
1 0.67 0.91 0.77 360
avg / total 0.82 0.78 0.78 880
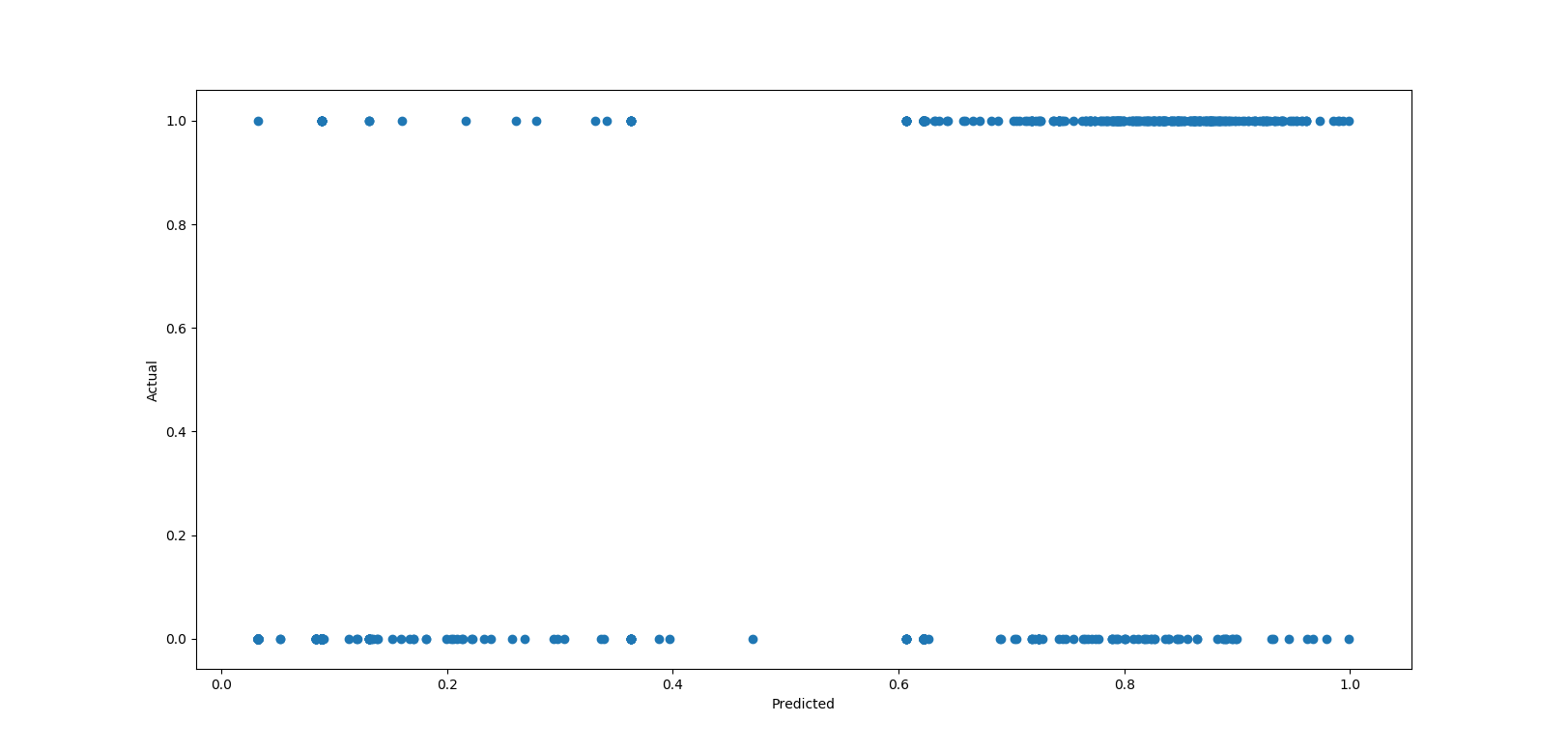
I then decided to check if the missing feature for how users found the site was the reason for the unexpected results in my Logistic model. To do this, I ran the balanced Logistic Regression on all the data that wasn’t linked to a user that signed up in December:
Mean accuracy of logistic regression classifier on test set: 0.8290398126463701
[[181 44]
[ 29 173]]
tn, fp
fn, tp
estimatedCoefficients features sort
0 1.660179 dup_protocol_started 1.660179
3 0.422823 usual_activity_len 0.422823
5 0.276151 bio_sex_answered 0.276151
9 0.272586 usual_diet_len 0.272586
7 0.269947 menstruation_yn 0.269947
1 0.221253 caffeine_yn 0.221253
2 0.184799 married_yn 0.184799
11 0.116015 usual_conditions_len 0.116015
4 0.109095 alcohol_yn 0.109095
10 0.076295 usual_medications_len 0.076295
8 -0.018323 blood_type_answered 0.018323
6 0.017111 bio_sex 0.017111
Estimated intercept: [-0.31948655]
With KFold cross validation
10-fold cross validation average accuracy: 0.77
10-fold cross validation average recall: 0.88
10-fold cross validation average precision: 0.73
precision recall f1-score support
0 0.86 0.80 0.83 225
1 0.80 0.86 0.83 202
avg / total 0.83 0.83 0.83 427
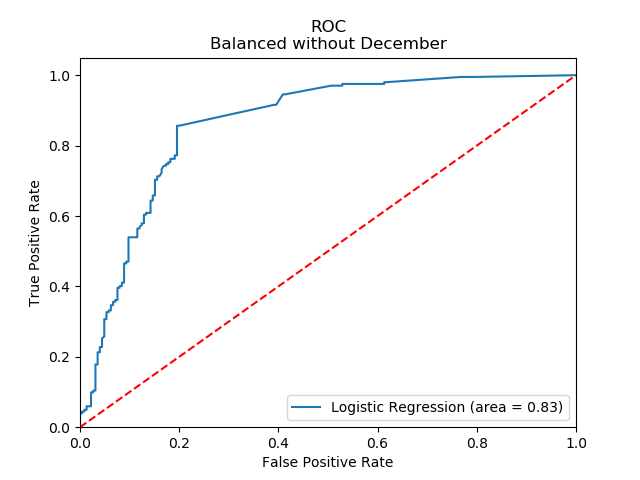
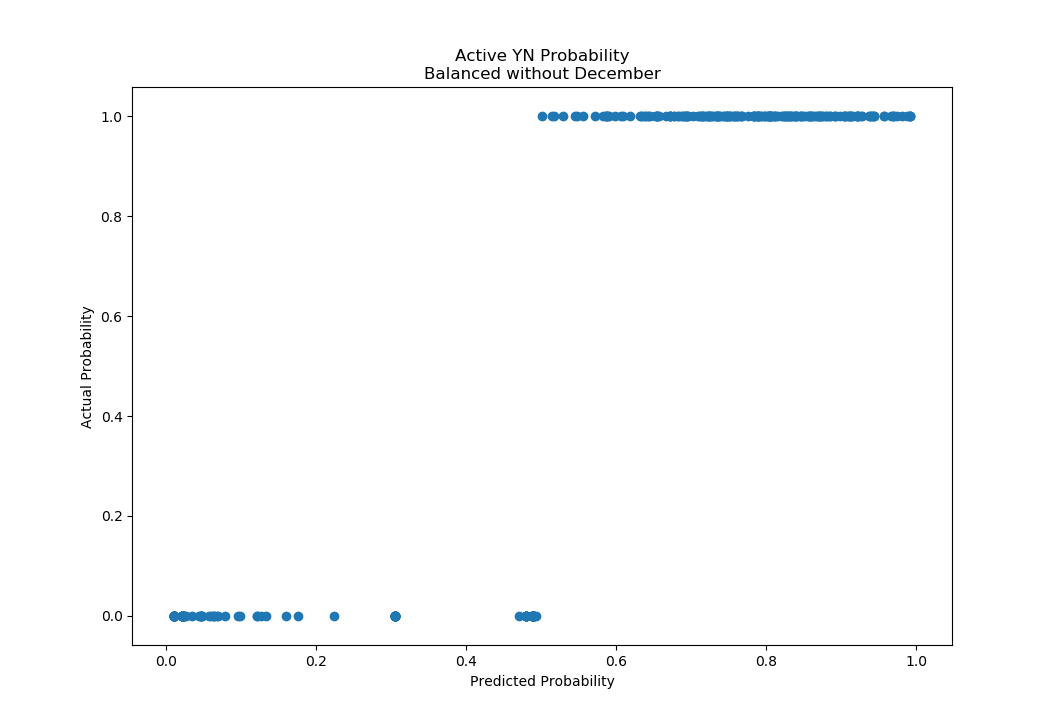
With the same cost matrix as before, I now get:
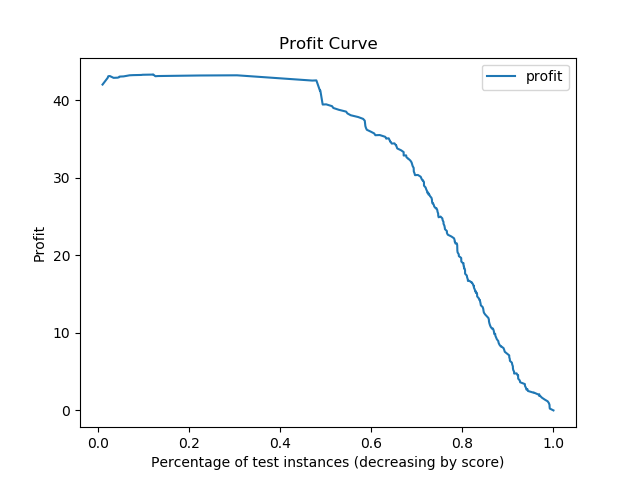
Based on the results of removing December, I believe the logistic model for whether or not a user will be active on the site will be improved by tracking how the user heard about the site.